Introduction
This Section will Introduce you the Ara Vector Processor.
Introduction to Ara
Ara is a modular, open-source vector processing unit designed to augment RISC-V processors with high-performance, energy-efficient vector computation. It is developed by the PULP platform at ETH Zurich and the University of Bologna.
At its core, Ara is a scalable vector accelerator compliant with the RISC-V Vector Extension 1.0 (RVV). It is specifically designed to target data-parallel workloads in embedded and high-performance computing environments. Ara is built to plug into the CVA6 RISC-V core, and is suitable for system-on-chip (SoC) designs that require vector processing capabilities for applications such as:
Signal processing
Linear algebra
Machine learning kernels
Computer vision
Ara can be configured with a power-of-2 number of parallel vector lanes ranging from 2 to 16. Each lane contains a slice of the Vector Register File (VRF), a SIMD FPU, and a SIMD ALU/Multiplier.
Since Multiply-and-Accumulate instructions can be executed in one cycle by each FPU, the maximum performance of Ara is 2 * #Lanes 64-bit packets/cycle, where each 64-bit packet can contain from one 64-bit element to eight 8-bit elements, processed in SIMD fashion.
Architectural Overview
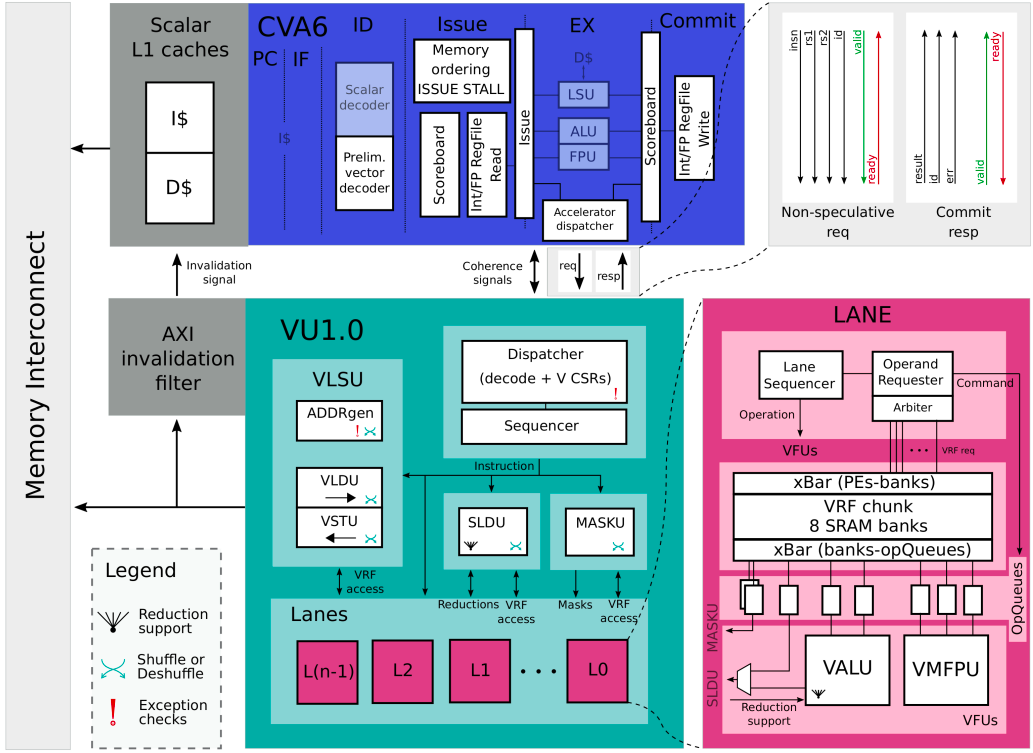
Ara’s top level diagram
Ara is composed of the following major components:
Vector Functional Units (VFUs): Includes ALUs, FPUs, multipliers, mask units, and slide units, each operating across multiple lanes in parallel.
Vector Lanes: The architecture is scalable to multiple lanes. Each lane processes one slice of the data, providing parallelism at the element level.
Dispatcher & Sequencer: These components decode and schedule vector instructions, ensuring synchronization and legal execution patterns.
Register File (VRF): Ara contains a large vector register file, partitioned across lanes for bandwidth scalability.
Memory Interface: Vector loads and stores are issued via AXI-compatible memory accesses, either from DRAM or TCDM (depending on system integration).
Ara is modular by construction: users can configure the number of lanes, supported datatypes (int/fixed/fp), and optional features like floating-point extensions or reductions.
Target Use Cases
Ara is ideal for:
Academic research into vector architectures and compilers
Hardware/software co-design
Custom accelerators in SoC designs
FPGA-based prototyping of RVV software
Ara for Non-Experts
What Is Ara?
Think of Ara as a muscle boost for a processor, specialized in handling repetitive data-heavy tasks—like multiplying a thousand numbers in parallel or transforming images efficiently.
Instead of performing one operation at a time, Ara handles many operations at once using vectors (think: long lists of numbers). This is similar to how modern GPUs work for games and machine learning—but in a way that is more tailored to embedded systems and open-source hardware.
Why Is Ara Useful?
Most general-purpose CPUs process one or two pieces of data per cycle. Ara can process dozens or hundreds of values in parallel. This makes it much faster and more energy-efficient when dealing with structured, repetitive workloads like:
Filtering an audio signal
Applying a blur effect on an image
Computing dot products in a neural network layer
Ara plugs into a RISC-V core like an add-on, offloading these “bulk” computations.